
A More Reasonable Benchmark for Your ML Model
How predicting ad clicks made me rethink what 'good enough' really means

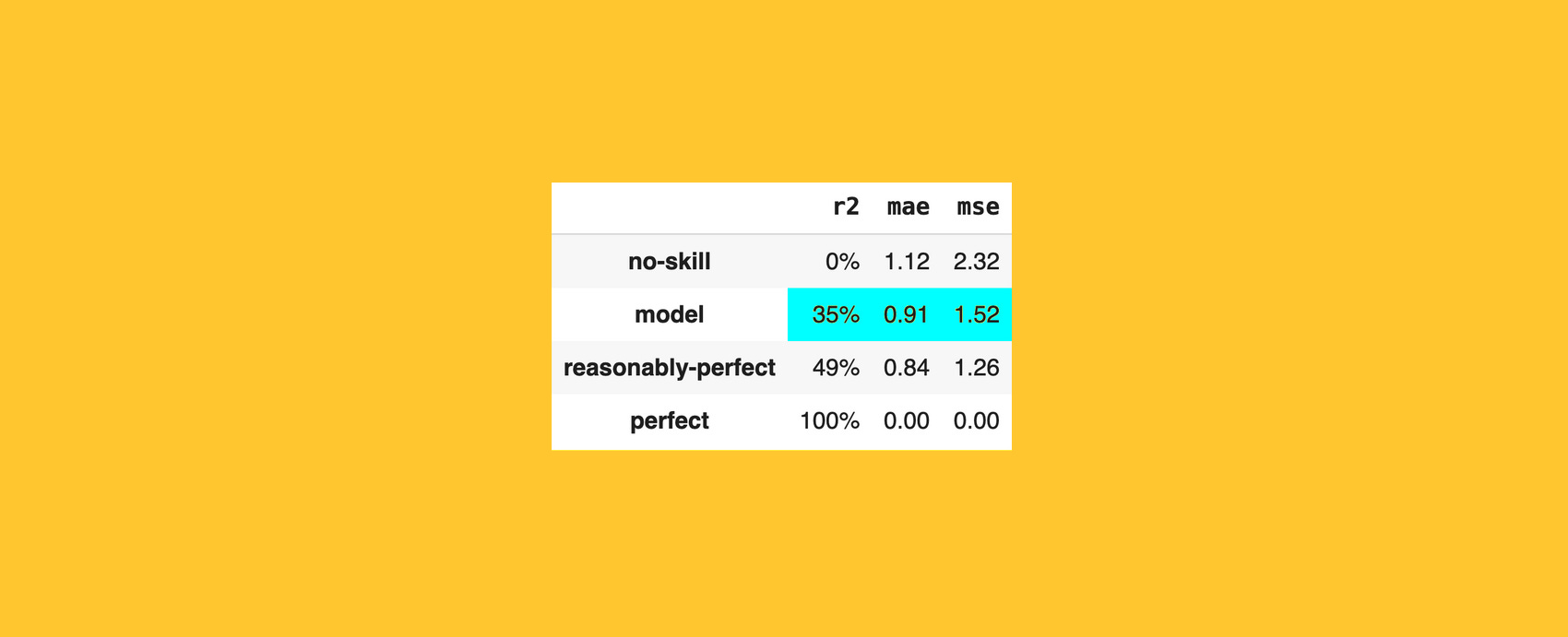
Deciding when a machine learning model is good enough is often challenging.
Practitioners usually compare their metrics to two extreme benchmarks: the worst case (usually called the no-skill model) and the best case (the hypothetical perfect model which makes zero-error predictions).
The problem is that, while the no-skill scenario provides a sensible baseline, measuring against a perfect prediction model is unrealistic: it’s simply not possible to achieve perfection in real-world data.
In this article, I’ll share a real-life experience from predicting ad clicks that made me realize just how misleading these traditional benchmarks can be. More importantly, I’ll explain how to define a more realistic baseline, one that offers practical insights and helps drive better modeling decisions.
Keep reading with a 7-day free trial
Subscribe to From Data to Decisions to keep reading this post and get 7 days of free access to the full post archives.